概要
この章では、Javaデータベース接続(JDBC)、Teradata JDBC Driver、クライアント システムのJavaプログラムをデータベースに接続する2階層アーキテクチャについて説明します。この章は、以下のセクションで構成されています。
新機能
Teradata JDBC Driverバージョン20.0の新機能
- TLS証明書の失効チェック(JDBC-191874、JDBC-191875)
- JDK/JRE 8以降が必要です
- JDK/JRE 7以前では動作しません
Teradata JDBC Driverバージョン17.20の新機能
- Apache Sparkの相互運用性のためのSTRICT_NAMES=OFF接続パラメータ (JDBC-191813)
- OpenID Connectによる柔軟な構成のためのOIDC_SCOPEおよびOIDC_TOKEN接続パラメータ (JDBC-191823)
- BROWSER_TIMEOUT接続パラメータ (JDBC-191811)
- クライアント システムの情報 の詳細を改善 (JDBC-191828)
- VPN切断/再接続による再接続の相互運用性 (JDBC-191829)
Teradata JDBC Driverバージョン17.10の新機能
- Teradata Advanced SQL Engine 16.20.53.30以降で使用可能なHTTPS/TLS接続 (JDBC-190758)
- Teradata Advanced SQL Engine 17.10以降で使用可能なブラウザ認証(JDBC-191772)
Teradata JDBC Driverバージョン17.0の新機能
- tdgssconfig.jarの消去 (JDBC-191761)
- Teradata Advanced SQL Engine 16.20以降で使用可能なJWT認証(JDBC-187068)
- JDK 13との互換性(JDBC-191770)
Teradata JDBC Driverバージョン16.20の新機能
- Teradata Advanced SQL Engine 16.20以降での新しいデータタイプDATASET STORAGE FORMAT CSVのサポート(JDBC-184941)
- Teradata Database 16.10以降のAIX、HP-UX、およびMacOSで利用できるKerberos認証(JDBC-184179)
Teradata JDBC Driverバージョン16.10の新機能
- 保存されたパスワード保護(JDBC-154936)
- Teradata Database 16.10以降でのTeradata Databaseの複数のハッシュマップのサポート(JDBC-174213)
- Teradata Database 16.10以降のUDT、Periods、XML、ST_Geometry、およびArrayとしてのJavaストアド プロシージャのパラメータのサポート(JDBC-124424)
- ResultSetMetaDataの動作を調整するためのMAYBENULLおよびCOLUMN_NAMEの接続パラメータのサポート(JDBC-183490, JDBC-185106)
- エラー テーブルのJDBC FastLoadおよびJDBC FastLoad CSV接続パラメータのサポート(JDBC-171880)
Teradata JDBC Driverバージョン16.0の新機能
- Teradata Database 16.0以降、最大1MBのサイズの大きな行に対応(JDBC-115666, JDBC-177265, JDBC-177267)
- Teradata Database 16.0以降、メッセージ サイズを大きくしてデータ転送パフォーマンスを向上(JDBC-177261)
- Teradata Database 16.0以降、Unicodeパス スルーに対応(JDBC-174886)
- Teradata Database 16.0以降、新しいデータ タイプDATASET STORAGE FORMAT AVROを導入(JDBC-176193)
- Teradata Database 15.10以降、ログオン メカニズムの自動選択でLOGMECH=TDNEGO接続パラメータを使用(JDBC-154836)
- LDAPおよびKRB5ログオン メカニズムでアカウント文字列をサポート(DR181560)
- JDBC 4.0 APIのDatabaseMetaData getFunctions、getFunctionColumns、getSchemas(String,String)(JDBC-163135)
- ParameterMetaDataおよびResultSetMetaDataのgetPrecisionメソッドでのJDBC 4.0 APIの動作(JDBC-156332)
- Teradata Database 16.0以降、DatabaseMetaData getColumnメソッドでHELPコマンドを回避(JDBC-154823)
- Teradata Database 16.0以降、DatabaseMetaDataメソッドでDBC.UDTInfoVおよびDBC.UDTTransformVビューを使用(JDBC-143102, JDBC-170532)
- LITERAL_UNDERSCORE=ON接続パラメータによりDatabaseMetaDataメソッドのパフォーマンスを向上(JDBC-179996)
- ResultSetカーソル動作メソッドのパフォーマンスを向上(DR182658)
- DNSルックアップの回数を減らしてログオン パフォーマンスを向上(JDBC-177757, JDBC-182168)
Teradata JDBC Driverバージョン15.10の新機能
- Teradata Database 15.10以降での小さいLOBの値のパフォーマンスが向上(JDBC-163202)
- JDBC 4.0 API仕様の新しいエスケープ構文のスカラー関数(JDBC-163170)
- SQL接続の接続isValidメソッド(JDBC-164061)
- MongoDBへのTeradata QueryGridコネクタのサポート(JDBC-173903)
- JDBC FastLoadおよびJDBC FastLoad CSVのCHATTER接続パラメータ(JDBC-171241)
- Teradata Database 15.10以降でのプロファイル クエリー バンド値のサポート(JDBC-170226)
- JDK 8のサポート
Teradata JDBC Driverバージョン15.0の新機能
- Teradata Database 15.0以降でのJSONデータ タイプのサポート(JDBC-162376)
- Teradata Database 14.10以降でのデータの暗号化の集中管理(JDBC-148040)
- "Linuxの遅延ログオン"問題の回避(JDBC-165341)
- STRICT_ENCODE接続パラメータ(JDBC-144415)
- JDBC FastLoad (JDBC-160027)およびJDBC FastExport (JDBC-160024)でのPERIODデータ タイプのサポート
- TIME WITH TIME ZONE、TIMESTAMP WITH TIME ZONE (JDBC-144698)、およびINTERVALデータ タイプ(JDBC-110776)のStruct値のサポート
- Teradata Database 14.10以降でのデータベース通信エラー後の自動再接続(JDBC-154833)
- Teradata Database 14.10以降でのデータベース再始動により中断されたSQLリクエストのリドライブ(JDBC-154881)
Teradata JDBC Driverバージョン14.10の新機能
- java.sql.Driver getPropertyInfoメソッドの実装(JDBC-55968)
- Teradata Database 14.10以降、64ビット アクティビティ カウントのサポート(JDBC-68722)
- 結果セットの保持機能CLOSE_CURSORS_AT_COMMIT (JDBC-99266)
- DatabaseMetaData getIndexInfoメソッドでの二重引用符を含む引数のサポート(JDBC-100184)
- PreparedStatementパラメータとして固定幅のBYTEデータ値を導入(JDBC-127422)
- Teradata Database 14.10以降、JDBC 4.0 SQLXMLデータ タイプを導入(JDBC-134645)
- Teradata Database 14.10以降での、JDBC FastLoadおよびJDBC FastExport GOVERN=OFFフェイルファストの導入(JDBC-153117)
- Teradata Database 14.10以降での、UTF8セッション文字セットでのコンソール パーティション接続のサポート(JDBC-156715)
- Teradata Database 14.10以降での、DatabaseMetaData getIndexInfoメソッドによる索引データベース名の指定(JDBC-159277)
- Raw接続用のscaleOrLength引数を持つPreparedStatement setObjectメソッドの導入(JDBC-160029)
- SHOW IN XMLコマンドのサポート(JDBC-160209)
- SQL以外の接続用のJDBC 4.0 APIメソッド(JDBC-160380)
- JDK 7のサポート(JDBC-162129)
Teradata JDBC Driverバージョン14.0の新機能
- JDBC 4.0 API仕様インターフェースのサポート(JDBC-107402)
- Teradata Database 14.0以降でのArrayデータ タイプのサポート(JDBC-138098)
- Teradata Database 14.0以降でのSQL NUMBERデータ タイプのサポート(JDBC-143362)
- JDBC FastLoad CSV接続で、CSV(カンマ区切り値)データを空の宛先表に効率的にロードできるようになった(JDBC-143576)
- Teradata Database 13.10以降でのStructuredおよびInternal UDT値へのjava.sql.Struct値の入力および出力(JDBC-115639)
- Teradata Database 13.10以降でのjava.sql.StructとしてのPERIODデータ タイプのサポート(JDBC-117048)
- Teradata Database 13.10以降でのDistinct型およびStructured型UDT値のアプリケーション カスタム タイプのマッピングのサポート(JDBC-115641)
- Teradata Database 14.0以降での強制アクセス制御(行レベル セキュリティ)のサポート(JDBC-129622)
- Teradata Database 14.0以降でのクライアント属性のサポート(JDBC-122378)
- Teradata Database 14.0以降でのUTF8およびUTF16セッション文字セットでのMonitor接続のサポート(JDBC-109963)
- データベース通信エラー後のTeradataセッションの再接続のサポート(JDBC-107800)
- DDSTATS接続パラメータ(JDBC-143408)
Teradata JDBC Driverバージョン13.10の新機能
- Teradata Database 13.10以降でのPreparedStatementバッチの行単位の成功状態およびエラー状態(JDBC-124457)
- Teradata Database 13.10 TASMワークロード管理のサポート(JDBC-123191)
- Teradata Database 13.10以降でのスプールなしのFastExport直接エクスポートのサポート(JDBC-122317)
- TIME WITH TIME ZONEおよびTIMESTAMP WITH TIME ZONEのサポートが改善された(JDBC-106222)
- Teradata Database 13.0以降でのGeospatial(地理空間)データ タイプのサポート(JDBC-132370)
- CONNECT_FAILURE_TTL接続パラメータ(JDBC-113453)
- TCPソケット オプションのTCP接続パラメータ(JDBC-131226、RFC 131929)
- CREATE/MODIFY USERで指定されたSTARTUP文字列のサポート(JDBC-130385)
- COPホスト名検出を制御するためのCOP接続パラメータ(JDBC-92048)
- Teradata Database 13.0以降での非基本索引テーブルのサポート(JDBC-121210)
Teradata JDBC Driverバージョン13.0の新機能
- tdgssjava.jarファイルはTeradata JDBC Driverで不要になった(JDBC-112569)
- Teradata Database 13.0以降でのJavaユーザー定義関数(UDF)のサポート(JDBC-115627)
- Teradata Database 13.0以降でのJavaストアド プロシージャから返される動的結果セットのサポート(JDBC-108348)
- DriverManager setLoginTimeoutまたはDataSource setLoginTimeoutでのログイン タイムアウト機能(JDBC-107027)
- JDBC FastExportで大量のデータを表およびビューから効率的にエクスポートできるようになった(JDBC-111264)
- Teradata Database 12.0以降に送信されるDATE、TIME、およびTIMESTAMP値の暗黙的なデータ タイプ変換が改善された(JDBC-69205)
- Teradata Database 12.0以降での、宛先CHAR/VARCHARに送信されるDATE値のY2K準拠の暗黙の変換(JDBC-69205)
- Teradata Database 13.0以降での信頼済みセッション(クエリー バンドPROXYUSERのユーザーの偽装)のサポート(JDBC-114956)
- Teradata Database V2R6.2以降でのLDAP認証用のgetConnectionパラメータのユーザー名とパスワードのサポート(JDBC-116276)
- Teradata Databaseホスト名としてのリテラルIPアドレスのサポート(JDBC-120378)
Teradata JDBC Driverバージョン12.0の新機能
- Teradata Database 12.0以降でのJavaストアド プロシージャのサポート(JDBC-101800)
- ユーザー定義関数(UDF)、ユーザー定義メソッド(UDM)、Javaストアド プロシージャ、および他の外部ストアド プロシージャ(XSP)を、クライアント クラスパス上のリソースから作成できる(JDBC-101277)
- Teradata Database 12.0以降でのSQLストアド プロシージャから返される動的結果セットのサポート(JDBC-102453)
- Teradata Database V2R6.2以降での更新可能結果セットのサポート(JDBC-51544)
- JDBC 3.0仕様のBlobおよびClob更新メソッドのサポート(JDBC-58075)
- JDBC FastLoad接続で、大量のデータを空の宛先表に効率的にロードできるようになった(JDBC-104893)
- JDBC Monitor接続でのデータベースの性能モニターおよびプロダクト制御機能へのアクセス(JDBC-100351)
- TIME値の小数秒がデータベースから返されるようになった(JDBC-104020)
- USEXVIEWS接続パラメータを使用したデータ ディクショナリXビューに対するDatabaseMetaDataクエリーのサポート(JDBC-92937)
- NEW_PASSWORD接続パラメータを使用したデータベースのパスワード有効期限のサポート(JDBC-92927)
- Teradata Database 12.0以降でのSET QUERY_BAND文のサポート(JDBC-102732)
- Teradata Database 12.0以降での複文要求のカーソル位置設定用のgetMoreResults(KEEP_CURRENT_RESULT)のサポート(JDBC-94241)
- Teradata Database 12.0以降でのSELECTリストのパラメータ マーカーのサポート(JDBC-107900)
ソフトウェア アップグレードの計画
リストされているJDBC仕様機能と動作のサポートを見越して、これらのJDBC仕様機能と動作に対応するようにアプリケーションを変更する必要があります。JDBC 3.0仕様では、executeQuery、executeUpdate、およびexecuteBatchの各APIに渡すSQLリクエストを妥当性検査するためにJDBCドライバとデータ ソースが必要です。また、SQLリクエストがAPIに不適切な場合、executeQuery、executeUpdate、およびexecuteBatchの各APIからSQLExceptionをスローする必要があります。
- 結果セットを返さないSQL文または複数の結果セットを返すSQL文でexecuteQueryを使用すると、SQLExceptionがスローされます。
- 結果セットを返すSQL文または複数の更新件数を返すSQL文でexecuteUpdateを使用すると、SQLExceptionがスローされます。
- 1つ以上のSQL文が結果セットを返すときにexecuteBatchを使用すると、SQLExceptionがスローされます。
Teradata JDBC Driverの現在のバージョンを特定する手順
Windows
Windowsに現在インストールされているTeradata JDBC Driverのバージョンを特定するためには、コマンド プロンプト ウィンドウを開いて、Teradata JDBC Driverが格納されているディレクトリに移動した後、次のコマンドを使用します。
jar xvf terajdbc4.jar META-INF/MANIFEST.MF
type META-INF\MANIFEST.MF
UNIXおよびLinux
UNIXおよびLinuxに現在インストールされているTeradata JDBC Driverのバージョンを特定するためには、Teradata JDBC Driverが格納されているディレクトリに移動した後、次のコマンドを使用します。
jar xvf terajdbc4.jar META-INF/MANIFEST.MF
cat META-INF/MANIFEST.MF
JDBCインターフェースの説明
JDBCは、アプリケーション プログラミング インターフェース(API)の仕様です。このAPIにより、プラットフォームに依存しないJavaアプリケーションは、SQLを使用してデータベース管理システムにアクセスできます。
JDBC APIは、次の項目に関するインターフェースの標準セットを提供しています。
これらのインターフェースを図1 と表2 に示します。
図1: JDBCインターフェース
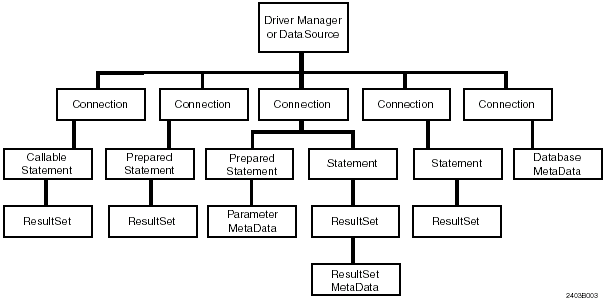
表2: JDBCインターフェース
|
|
|
|
|
バイナリ ラージ オブジェクト(BLOB)のサポートを提供する。
|
|
|
文字ラージ オブジェクト(CLOB)のサポートを提供する。
|
|
|
|
java.sql.DatabaseMetaData
|
選択したデータベースに関するさまざまな情報にアクセスする。
|
|
|
データベース接続の作成や取得のサポートを提供する。
|
|
|
ドライバをロードして、データベース接続の新規作成をサポートする。
|
java.sql.ParameterMetaData
|
|
java.sql.PreparedStatement
|
特定の接続上でプリペアードSQL文を実行するためのコンテナとして動作する。
|
|
|
|
java.sql.ResultSetMetaData
|
|
|
|
指定の接続上でSQL文を実行するためのコンテナとして動作する。
|
Java.sql.CallableStatement
|
指定の接続に対してデータベース上でストアド プロシージャを実行するためのコンテナとして動作する。
|
javax.sql.ConnectionEventListener
|
PooledConnectionにより生成されたイベントを受信するよう登録するオブジェクトとして動作する。
|
javax.sql.ConnectionPoolDataSource
|
PooledConnectionオブジェクト用のファクトリーです。このインターフェースを実装するオブジェクトは、一般にJava Naming and Directory Interface (JNDI)サービスによって登録されます。
|
javax.sql.PooledConnection
|
接続プール管理用のフックを提供する接続オブジェクトです。PooledConnectionオブジェクトは、データ ソースへの物理的接続を表わします。
|
Teradata JDBC Driverの説明
Teradata JDBC Driverは、JDBCインターフェースを使用するJavaクラスのセットです。そのため、Java言語を使用してTeradata Vantage™にアクセスできます。図2 に表示されているように、Teradataは現在、Type 4のJDBCドライバに対応しています。
図2: JDBCインターフェース

Type 4 JDBCドライバ
Type 4 JDBCドライバはデータベースと直接通信します。
JDBC Type 4アーキテクチャ
説明
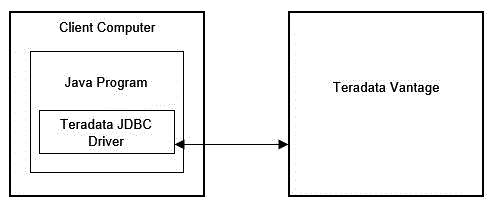
Teradata JDBC Driverは、図3 に示すように、2階層のアーキテクチャを使用してデータベースにアクセスします。
図3: JDBC Type 4アーキテクチャ
動作の概要
Teradata JDBC Driverはプラットフォームに依存しないため、サポートされているJava仮想マシン(JVM)がインストールされているすべてのシステムで使用できます。
Teradata JDBC DriverのJavaクラスは、TCPソケットを使用してデータベースに直接接続されます。
利点
2階層のアクセス アーキテクチャには、次の利点があります。
- JDBC Type 3ドライバに比べて、パフォーマンスが優れている。
- Javaドライバがどこでも実行できる。
多国語機能のサポート
Java仮想マシン ロケール
Teradata JDBC Driverは、日本語ロケールをサポートしています。この結果、JVMに日本語ロケールが使用されている場合、Teradata JDBC Driver例外メッセージ テキストは日本語で表示されます。
java -Duser.language=ja -Duser.country=JP
これは、Teradata JDBC Driverの例外条件にだけ適用されます。データベースのエラー条件の例外メッセージ テキストは、データベースにより表示されるため、JVMロケールで制御されません。
日本語ロケール以外のすべてのロケールでは、Teradata JDBC Driver例外のメッセージ テキストは英語で表示されます。
JavaアプリケーションからTeradata JDBC Driverへのデータの流れ
JDBC APIを含むほとんどすべてのJava APIで、java.lang.Stringオブジェクトの使用が想定されています。このオブジェクトには、Unicode文字が入っています。
文字データは、通常、java.lang.StringオブジェクトとしてJavaアプリケーションからTeradata JDBC Driverに渡されます。これはアプリケーションが以下の場合に起こります。
- SQL文字列リテラルとして文字データをSQL文に含む場合。この操作では、Statement.execute、Statement.executeUpdate、Statement.executeQuery、またはConnection.prepareStatementなどのJDBC APIの1つを使用します。
- プリペアード文を使用している場合。この操作では、JDBC APIメソッドPreparedStatement.setStringまたはPreparedStatement.setObject(String)を使用して、? (疑問符)パラメータ マーカーに文字データをバインドします。
Teradata JDBC Driverにjava.lang.Stringオブジェクトとしてデータが渡されると、Teradata JDBC Driverは非UnicodeからUnicode文字への変換を実行しません。これは、java.lang.Stringオブジェクトには必ずUnicode文字が入っているからです。
Javaアプリケーションが非Unicode文字を取得し、これらの文字をデータベースに格納する、例外的なシナリオが2つあります。これらは、一般的なアプリケーション開発シナリオではありません。というのは、一般的なJavaアプリケーションはもっぱらUnicodeベースで開発されるからです。
- シナリオ1: Javaアプリケーションが、何らかの方法で非Unicode文字データを取得する。例えば、TCPソケットから読み取って、その非Unicode文字データをバイト形式でJavaバイト配列に格納する。
- シナリオ2: Javaアプリケーションが、ファイル システム上のファイルから非Unicode文字データを読み取らなければならない。
シナリオ1では、非Unicode文字列データがJavaバイト配列にバイト形式で格納されている状態で、Javaアプリケーションは、次のjava.lang.Stringコンストラクタを使用します。
String(byte[] bytes, String charsetName)
この結果、指定した文字セットを使用して指定したバイト配列をデコードした、新しいStringが作成されます。java.lang.Stringオブジェクトを作成したら、JavaアプリケーションはほかのJava Stringオブジェクトと同じようにこのオブジェクトを操作できます。また、Teradata JDBC Driverにこのオブジェクトを渡すことができます。
シナリオ2では、非Unicode文字列データがファイル システム上のファイルに格納されている状態で、Javaアプリケーションは、ファイルからの入力データを表わす? (疑問符)パラメータ マーカーの付いたPreparedStatementオブジェクトを使用します。このとき、Javaアプリケーションは、次のJDBC APIのどれかを使用します。
- PreparedStatement.setCharacterStreamは、どの文字セットでも、ファイルに格納されているデータに使用できます。JDBC API PreparedStatement.setCharacterStreamを使用するには、その引数の1つであるReaderオブジェクトを、Javaアプリケーションが提供する必要があります。PreparedStatement.setCharacterStreamでは、適切なJava I/O APIを使用して非Unicode入力データをUnicodeに変換し、変換の結果データ損失がないことを保証するのはJavaアプリケーションの責任です。
Javaアプリケーションは、FileInputStreamオブジェクト上でInputStreamReaderオブジェクトを作成した後、JDBC API PreparedStatement.setCharacterStreamに引数としてInputStreamReaderオブジェクトを渡します。
InputStreamReaderオブジェクトを作成する場合、Javaアプリケーションは、文字セットパラメータを持つInputStreamReaderコンストラクタの1つを使用します。また、Javaアプリケーションは、ファイルに格納されているデータの適切な文字セットを指定します。
例:
prepstmt.setCharacterStream(columnIndex, new InputStreamReader(new FileInputStream("myfile.dat"),"ISO-8859-8"))
- PreparedStatement.setAsciiStreamは、情報交換用米国標準コード(ASCII)文字セットの場合に限り、ファイルに格納されているデータに使用できます。JDBC API PreparedStatement.setAsciiStreamを使用するには、その引数の1つであるInputStreamオブジェクトを、Javaアプリケーションが提供する必要があります。
Javaアプリケーションは、ASCIIファイルから読み取るFileInputStreamオブジェクトを作成した後、JDBC API PreparedStatement.setAsciiStreamに引数としてFileInputStream オブジェクトを渡します。
例:
prepstmt.setAsciiStream(columnIndex, new FileInputStream("ascii.txt"))
Teradata JDBC Driverとデータベース間のデータフロー
Teradata JDBC Driverは、Javaアプリケーションがデータベース セッションに対してセッション文字セットを指定できるように、CHARSET接続パラメータを提供します。CHARSET接続パラメータについての説明は、「Teradata JDBC Driverの使用」に記載の「データベース接続パラメータ」の表を参照してください。JavaアプリケーションがCHARSET接続パラメータを指定しない場合、デフォルト設定のCHARSET=ASCIIが使用されます。
推奨は、Javaアプリケーションが、データベースのUnicode列に文字データを格納し、UTF8セッション文字セット(接続パラメータCHARSET=UTF8)を使用することです。この結果、文字セット間の変換を回避できるため、文字データのエンドツーエンドの忠実性を保証できます。
Teradata JDBC Driverは、表3 で示しているように、Teradataセッション文字セットからJava文字セットへの固定マッピングを提供します。特定のTeradataセッション文字セットに対して、対応するJava文字セットを使用して、データベースに送信するバイトをエンコードし、データベースから受信したバイトをデコードします。
CLIENT_CHARSET接続パラメータを使用すれば、Teradata JDBC DriverのTeradataセッション文字セットからJava文字セットへの通常マッピングを上書きできますが、CLIENT_CHARSET接続パラメータは、Teradataの新規展開で使用するためのものではありません。これはレガシー サポート機能であり、データベースでサポートされない使用方法からの移行を支援するためのものです。ここで、サポートされない使用方法とは、非Latin文字をLatin列に格納し、ASCIIセッション文字セットを使用して非ASCII文字へのサポートされないアクセスをすることです。 CLIENT_CHARSET接続パラメータで誤ったJava文字セットを指定すると、データ破損が発生します。CLIENT_CHARSET接続パラメータが使用されている場合、Teradataはデータの忠実性または品質を保証できません。
文字マッピングの違い
表4 に、特定の文字セットで特定の文字コード ポイントがどのように異なるかを記載します。
- Javaアプリケーションでは、Teradataセッション文字セットに対応するJava文字セットで表すことができない文字の使用を避けてください。
- Javaアプリケーションで、上述したPreparedStatement.setCharacterStream技法を使用する場合、Javaアプリケーションでは必ず、InputStreamReaderコンストラクタの引数に指定したJava文字セットが、ファイルに格納された非Unicode文字からUnicodeへのマッピングを提供します。
Javaアプリケーションが、CHARまたはVARCHAR列にWAVE DASHまたはMINUS SIGN文字を格納しようとすると、データベースは、この要求を適切に処理できません。これは、WAVE DASHおよびMINUS SIGNの各文字のSJIS、EUC、およびEBCDICコード ポイントに複数のUnicode文字変換があるからです。
データベースは、各セッション文字セットでU+FF5Eを次の外部コード ポイントにマップします。次のマッピングには、データベース マップ ファイルが必要になります。
- KANJIEBCDIC 0x43A1
- KANJIEUC 0xA1C1
- KANJISJIS 0x8160 1-
- mapeuc: UNICODE_2_UPC_CS123 0xFF5E 0xA1C1 # FULLWIDTH TILDE 2-
- mapsjis: UNICODE_2_SJIS_MBC 0xFF5E 0x8160 # FULLWIDTH TILDE 3-
- mapsosi: UNICODE_2_SOSI 0xFF5E 0x43A1 # FULLWIDTH TILDE
Teradata JDBC DriverからJavaアプリケーションへのデータフロー
問合わせの実行後、Javaアプリケーションは、通常、次のJDBC APIのどれかを使用して、文字データをjava.lang.StringオブジェクトとしてTeradata JDBC Driverから取得します。
- ResultSet.getString
- CHARまたはVARCHAR列のResultSet.getObjectはStringオブジェクトを返します。
または、Javaアプリケーションは、次のJDBC APIのどれかを使用して、文字データをTeradata JDBC Driverから取得できます。
- Unicode文字を提供するReaderオブジェクトを返す、ResultSet.getCharacterStream
- ASCII文字のみを提供するInputStreamオブジェクトを返す、ResultSet.getAsciiStream。Javaアプリケーションでは、このJDBC APIを使用して非ASCII文字データを取得しようとしないでください。
SQL文の修正
リリース3.1以前のTeradata JDBC Driverでは、アプリケーションがwhere句が指定されている?に対してsetNull()を呼び出した場合は必ず、出現した?をすべてIS NULLに置き換えて、SQL文を修正していました。
例えば、SQL文が以下の場合を考えます。
SELECT * from table1 where colid = ?
ここでアプリケーションがsetNull(1)を呼び出すと、Teradata JDBC DriverはSQL文を次のように書き換えていました。
SELECT * from table1 where colid is null
これは、SQL文がcolidがNullである行をすべて戻してしまうため、正しい使用方法ではありません。正しいSQL文は次のようになります。
SELECT * from table1 where colid = null
NullはNull自身を含めいずれの値とも等しくないため、この文は行を戻さない点に注意してください。
この問題は、リリース3.2のTeradata JDBC Driverで修正されましたが、修正によりいくつかのアプリケーションの出力が変更される可能性があります。
Null式のポリシー
『Teradata Database SQL関数、演算子、式および述部』には、null値を伴う比較(=等号演算子を含む)の結果について、次に示すポリシーが記載されています。
比較するいずれかの式がNULLの場合、比較結果は不明です。
比較するフィールドがNULLとなる場合に比較結果としてTRUEを提供するには、文にIS [NOT] NULL演算子が含まれている必要があります。
SQL文の訂正
リリース3.3ドライバでは動作しない不正なSQL文を修正するには、例として次の情報を活用してください。
アプリケーションが次のようなSQL文を使用する場合を考えます。
SELECT * from table1 where colid = ?
ここで、アプリケーションがnull値の引数または非null値の引数のいずれかを?パラメータとバインドしても、アプリケーションはどちらの場合にも=比較演算子がTrueを戻すと期待しているかも知れません。これは、リリース3.1以前のTeradata JDBC DriverはこのSQL文を修正し、その動作を提供するからです。
もしアプリケーションがその動作を期待する場合、SQL文を以下の通り変更します。
SELECT * from table1 where colid = ? or ? is null and colid is null
さらに、アプリケーションを変更し、引数を両方の?パラメータに2回バインドします。